
How Can We Help?
101 – Compression
Loss·y Compression




lossy compression or irreversible compression is the class of data encoding methods that uses inexact approximations and partial data discarding to represent the content. These techniques are used to reduce data size but will also degrade the image as the original pixel data is gone
Loss·less Compression

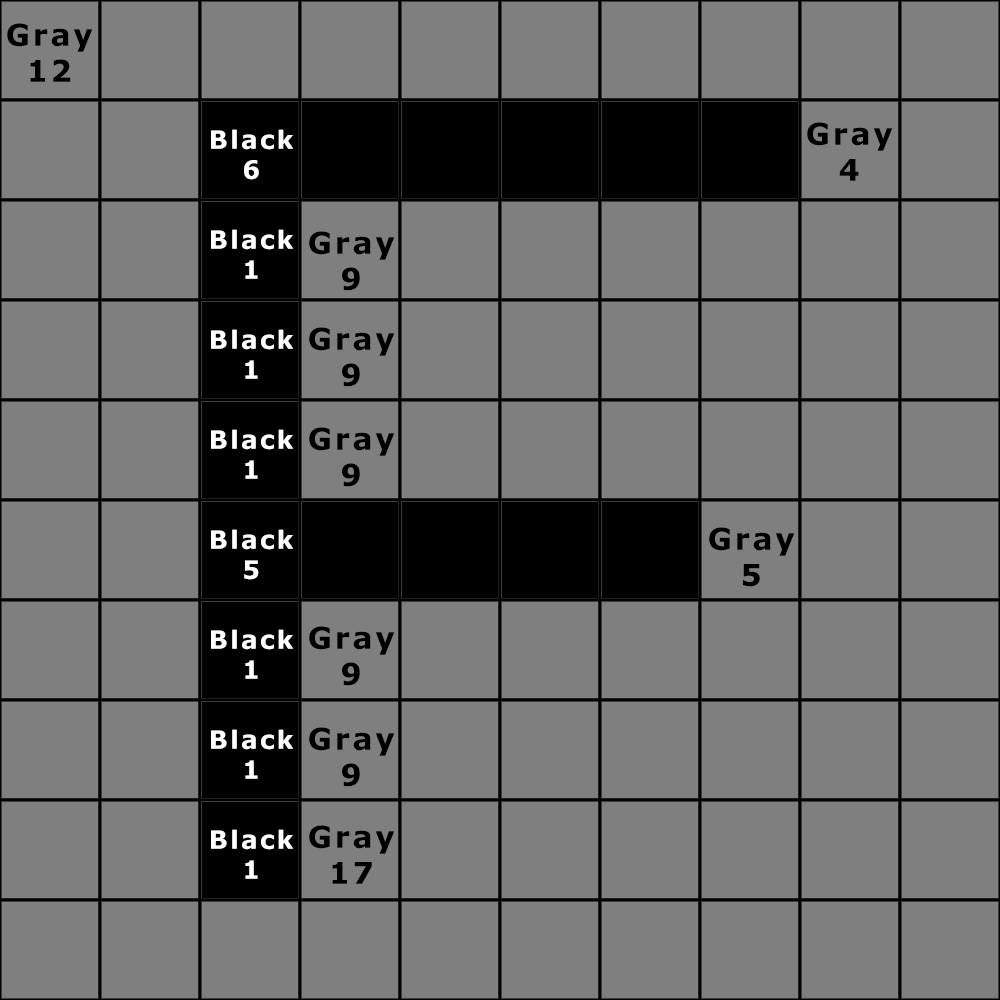

Lossless compression is a method of data compression in which the size of the file is reduced without sacrificing image quality. Unlike lossy compression, no data is lost when this method is used. Because the data is preserved, the technique will decompress the data and restore it exactly to its original state.
Run-length encoding (RLE)
Run-length encoding (RLE) is a very simple form of lossless data compression in which runs of data are stored as a single data value and count, rather than as the original run. This is most useful on data that contains many such runs. Consider, for example, simple graphic images such as icons, line drawings, and mostly black pixels. It is not useful with files that don’t have many runs as it could greatly increase the file size.

Video Compression
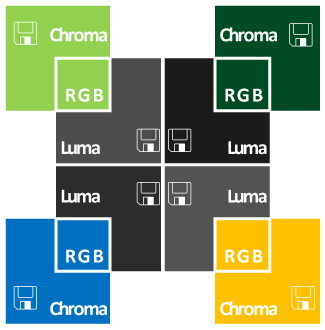
4 : 4 : 4
No compression and transports both luminescence and color data entirely
- ProRes 4444 (HD)
- DNxHD 444
- Cineform 12-bit HD
- Uncompressed HD 10-bit 4:4:4
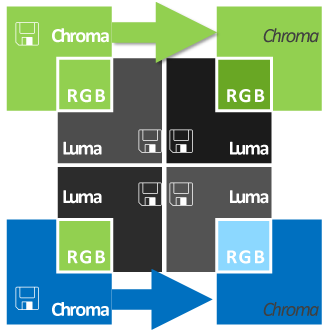
4 : 2 : 2
Half the sampling rate horizontally, but will maintain full sampling vertically.
- ProRes 422 HD, UHD, HQ & LT
- DNxHD & DNxHR
- Cineform 10-bit HD & UHD

4 : 2 : 0
Sample colors out of half the pixels on the first row and ignores the second row of the sample completely.
- h.264 HD & UHD